In linear regression, you fit the model
(1) 
However, often the relationship between your  and
and  variables is not linear, and transformations are required. Let’s look at some cases where log transformations of features are appropriate. One primarily transforms features to achieve linearity.
variables is not linear, and transformations are required. Let’s look at some cases where log transformations of features are appropriate. One primarily transforms features to achieve linearity.
Untransformed and Log Terms
Consider the model
(2) 
This implies that a unit change in
 leads to an expected change in of
leads to an expected change in of  , holding
, holding  fixed. That is, changes slowly as a function of . Let’s generate synthetic data from a model like this. We’ll generate data, fit the wrong model, and look at the fitted vs residuals plot.
fixed. That is, changes slowly as a function of . Let’s generate synthetic data from a model like this. We’ll generate data, fit the wrong model, and look at the fitted vs residuals plot.x1=runif(100,0,2)
x2=rnorm(100,0,10)
eps=rnorm(100,0,1)
y=rep(0.25,100)+7*log(x1)+2*x2+eps
plot(lm(y~x1+x2))
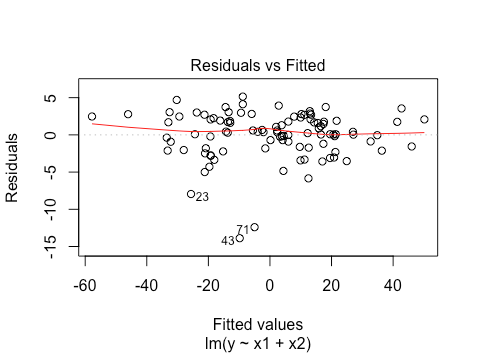
It looks pretty linear, despite fitting a linear model to a non-linear relationship. This is because  grows sub-linearly and , so the linear part
grows sub-linearly and , so the linear part  dominates.
dominates.
Log Only
However, if we remove the dominating term, we see
y=rep(0.25,100)+7*log(x1)+eps
plot(lm(y~x1))
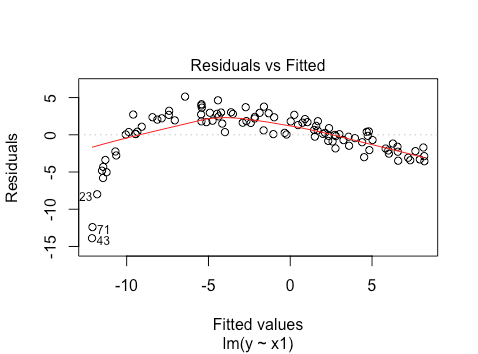
this is clearly non-linear, and looks similar in shape to the graph of plotting  in Google, although the latter is strictly increasing
in Google, although the latter is strictly increasing
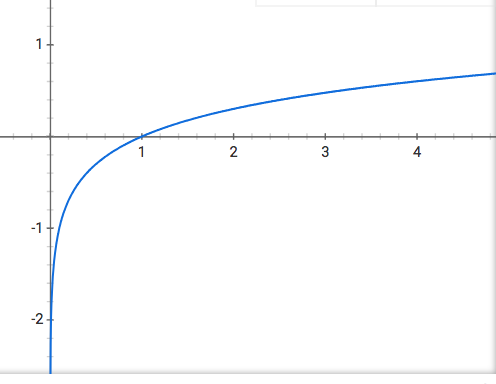
In conclusion, having an un-transformed covariate where the true relationship involves the log of the covariate is generally difficult to detect from the fitted vs residual plot when some other term dominates: however, for hypothesis tests and inferences to be correct, this needs to be handled. In some cases given that it can be difficult to detect empirically, one may want to think about theoretical relationships between features/covariates and responses.
As a further comment, you may note that the true log plot looks like it could be approximated pretty well via a two or three piece piecewise linear function. Over some ranges of the untransformed covariate, fitting a linear model is not bad, as long as you don’t expect the fit to extrapolate well.