When you start you should learn a few basic algorithms and understand them well. Here are five good ones.
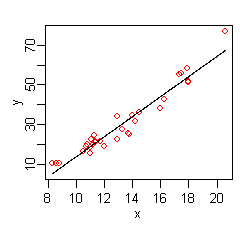
Linear Regression: this is one of the most important models to understand. It is useful for several reasons. Firstly, it can serve as a training tool to teach the basics of inference, prediction, and regression. Secondly, the classic model is the basis for many other fields: classical time series, longitudinal data analysis, high dimensional regression, and more. Third, even ordinary least squares (OLS) is itself still very useful, and for many applied problems will still give competitive accuracy in prediction and/or be the appropriate tool for inference. For an article on the basics of regression via checking assumptions, see https://boostedml.com/2018/08/testing-linear-regression-assumptions-the-kaggle-housing-price-dataset.html. To learn linear regression in more detail, a great resource is the econometrics class on Coursera.

Support Vector Machine (SVM): everyone should learn the basics of at least one classifier. Support vector machines have elegant math and intuition. They also lend themselves to more computationally efficient use of kernel methods, which allow handling of non-linearities in the data, than some other classifiers. Note that understanding the math of even linear SVMs is non-trivial and goes into some details from convex optimization, which is important. The math of kernel methods can get quite a bit more complicated and uses functional analysis. While understanding the math deeply is always better, we can often get away with applying the packages (such as sci-kit learn) directly and seeing how performance changes under different scenarios: choices of kernel, changes in distribution of synthetic data, etc. This is useful even when you do understand the math. The best resource I’ve found for learning the basics of SVMs is the Stanford CS 229 class.
Bagging: ensemble methods are important for improving performance of classifiers or regressors. Many people win Kaggle competitions by using ensemble methods. Knowing tricks like this to improve accuracy for classification and regression is useful. The following post on Quora gives a good overview for when to use bagging.

K-means: often instead of trying to predict a response, we want to cluster our data into groups. For instance, say we want to stratify hospital patients into groups to try to understand how patients differ across groups. K-means could be the right tool. In k-means, we have a ‘hard’ assignment, where each patient is assigned to a single cluster.

Gaussian Mixture Models: what if we want to capture uncertainty in which cluster a participant is in? That is, we want a ‘soft’ assignment. In the case of hospitals patients, this means that instead of assigning a patient to a single cluster, we give them a probability distribution over all the clusters. A Gaussian mixture model is one way to do this. Here, we have several clusters, or components, and each component has a Gaussian observation distribution. We want to learn the prior probability of being in each component, and the observation distributions. K-means is actually a special case of this, where the variance of each component tends to  . The best resource I’ve found for studying Gaussian Mixture models is Chris Bishop’s PRML.
. The best resource I’ve found for studying Gaussian Mixture models is Chris Bishop’s PRML.