Introduction
In this post we describe attention mechanisms by motivating it using geometric intuition. The ideas are largely based on two somewhat theoretical papers: [1] and [2], but we focus on the core intuition from those papers rather than the theory.
A classic technique in both machine learning and statistics is to take weighted averages as a pre-processing step. For instance, in time series, one might take a moving average of the time series to smooth it. Based on the importance of neighboring information, this could assign uniform weights (simple moving average) or have different types of decay of importance as a function of time. In image data, convolutions perform a similar task. However, they are strictly speaking a not expectations since the weights may not make a valid probability mass function (pmf). These convolutions can blur an image or magnify important aspects of the image.
One extension of these ideas is to let the weights themselves be a mapping from the input objects that one takes a weighted average over to a vector of weights. In time series, this would mean that the moving average weights for a sliding window are themselves a mapping from the sliding window. They then vary as we move the sliding window. We’d like to choose these weights to achieve two tasks. The first isto reflect the ‘importance’ of specific locations (times, pixel locations). The second is to help achieve good performance in prediction tasks. This is the core basic motivation of the attention mechanisms in use today.
Outline
We start by defining an attention mechanism, describing why choosing the attention weights is the key challenge. Next we describe a very naive idea: choosing the attention weights to point in approximately the same direction as the input vector (sliding window). We describe a first attempt at this, maximizing the between the attention weights and the input vector, and why this doesn’t actually lead to pointing in approximately the same direction, and that it will also fail for multi-dimensional observations.
Following this naive idea, we then argue that adding a regularizer (for instance Shannon entropy) to the optimization problem does lead to pointing in approximately the same direction. This idea is too naive in practice and will also fail for multi-dimensional observations, but by replacing the data with another representation or summary, we obtain a workable idea that is in fact what many attention models use. With these two extensions to a very naive idea, we can recover softmax attention in the form that many papers use today. Again, these ideas primarily come from [1] and [2] but are presented in a much more mathematical way.
What is an Attention Mechanism
An attention mechanism involves three parts, and refers to calculation of the first. 1) a context vector 2) an attention weight probability mass function (pmf) 3) a value function. The context vector is given by
(1) ![\begin{align*}c&=\mathbb{E}_p[V(T)]\end{align*}](https://boostedml.com/wp-content/ql-cache/quicklatex.com-34d8852197d049b6320153abafc12acb_l3.png "Rendered by QuickLaTeX.com")
The parts are as follows:
- The context vector
 is a weighted average of a representation of data. This is used as input to a prediction model, such as a neural network.
is a weighted average of a representation of data. This is used as input to a prediction model, such as a neural network. - is a location in the domain or set of locations . could be the set of times in a sliding window, a set of pixel locations, etc.
- The attention weights , which is a discrete pmf describing the importance of locations .
- is a random variable drawn from .
- is a representation of the data at location .
 is a location in the domain or set of locations
is a location in the domain or set of locations  .
.  , which is a discrete pmf describing the importance of locations
, which is a discrete pmf describing the importance of locations  is a random variable drawn from
is a random variable drawn from  is a representation of the data at location
is a representation of the data at location Intuitively,  might be a vector representation of a word at position
might be a vector representation of a word at position  in a sequence, and we’re interested in taking a weighted average over a sequence of words and use that to perform some prediction task such as predicting the next word, classifying a sentence or document, etc.
in a sequence, and we’re interested in taking a weighted average over a sequence of words and use that to perform some prediction task such as predicting the next word, classifying a sentence or document, etc.
The important question is what should p the attention weights be? What properties do we want  to have, and how do we formulate as the solution to an optimization problem so that it has these properties? Intuitively, we would like weights that help us make good predictions.
to have, and how do we formulate as the solution to an optimization problem so that it has these properties? Intuitively, we would like weights that help us make good predictions.
Naive Attention Weights
One very naive idea, which it turns out is surprisingly close intuitively to what attention models do in practice, is make ‘ similar to  ,’ our data that we are taking a weighted average over. A good start would be using unnormalized cosine similarity or
,’ our data that we are taking a weighted average over. A good start would be using unnormalized cosine similarity or  inner product and trying to maximize that, subject to the constraint that
inner product and trying to maximize that, subject to the constraint that  the simplex i.e. is non-negative and sums to
the simplex i.e. is non-negative and sums to  . This ‘hopefully’ makes point in approximately the direction of .
. This ‘hopefully’ makes point in approximately the direction of .
The optimization problem for this is
(2) 
where  is the angle between and . This idea gives us a good direction to start with, but has some serious flaws:
is the angle between and . This idea gives us a good direction to start with, but has some serious flaws:
- It is too naive and would be unlikely to actually help prediction
- We need and to lie in the same vector space. This only holds if is a set of scalars. If is a set of vectors (say vector representations of words, then this won’t hold).
- It doesn’t actually make the optimal point in the direction of the data . By the fundamental theorem of linear programming, some standard basis vector will be a solution to the optimization problem. We can see this in the figure below.
 will be a solution to the optimization problem. We can see this in the figure below.
will be a solution to the optimization problem. We can see this in the figure below.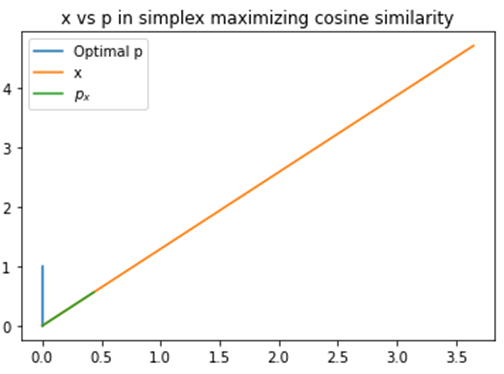 , we wanted to point in approximately the direction of the data , but due to the fundamental theorem of linear programming, maximizing unnormalized cosine similarity doesn’t actually achieve this, as we see. It simply gives us
, we wanted to point in approximately the direction of the data , but due to the fundamental theorem of linear programming, maximizing unnormalized cosine similarity doesn’t actually achieve this, as we see. It simply gives us  . This is not very useful: is there some similar optimization problem that will give us a solution that does approximately point in the direction of the data?
. This is not very useful: is there some similar optimization problem that will give us a solution that does approximately point in the direction of the data?Regularizing the Optimization Problem
We can avoid the pitfall of having standard basis vectors as a solution by including a regularizer.
(3) 
If we let  be Shannon entropy, then the solution to this is
be Shannon entropy, then the solution to this is
(4) 
which is very close to the softmax attention that many people use in practice. However, they tend not to use the original data , but instead use some transformation or summary of it. Let’s look at what the solution looks like again in the 2d case.
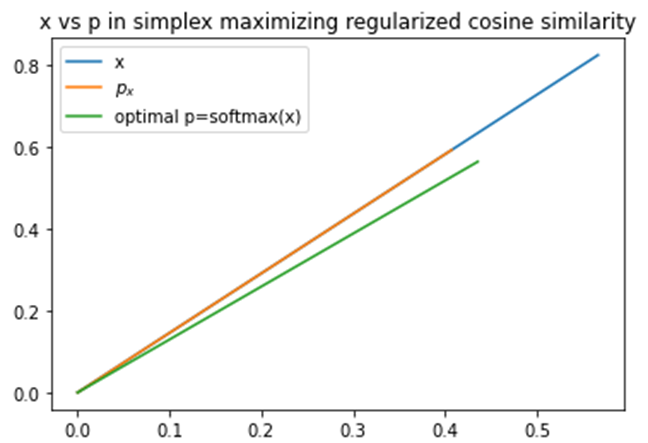 and are not in the same vector space we cannot do this.
and are not in the same vector space we cannot do this.However, we still have the problem that if is a set of  vectors instead of scalars, the inner product we used isn’t valid as it needs to be between two vectors.
vectors instead of scalars, the inner product we used isn’t valid as it needs to be between two vectors.
Summarizing the Data
We can extend the naive attention weights by replacing with a vector summarizing or representing it. Instead of maximizing the regularized unnormalized cosine similarity between and , where the latter may be a matrix instead of a vector (which isn’t valid), we maximize the similarity between and a summary  of . The summary maps
of . The summary maps  . This maps an
. This maps an  matrix to a vector of scalars. We then want to solve
matrix to a vector of scalars. We then want to solve
(5) 
We’re making a location ‘important’ i.e. giving it a large attention weight if its summary value is large in that direction, while constraining the attention weights to form a valid pmf. The next figure visualizes this.
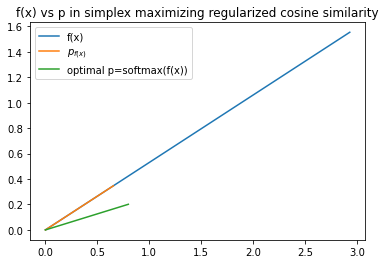 (potentially a matrix) with another representation (a vector), where
(potentially a matrix) with another representation (a vector), where  will be learned, and making point in approximately that direction, we can now handle the case where is a matrix. We also gain flexibility that will be useful for our final prediction task, since will be learned end-to-end with the prediction model to help make good predictions.
will be learned, and making point in approximately that direction, we can now handle the case where is a matrix. We also gain flexibility that will be useful for our final prediction task, since will be learned end-to-end with the prediction model to help make good predictions.Parametrizing the Summary
We still need a form for . One simple form lets  be a linear combination of basis functions of . One can let the weights map from to a vector. This gives
be a linear combination of basis functions of . One can let the weights map from to a vector. This gives
(6) 
We can use a rich or a simple form for  , including a neural network, a linear transformation, or some other transformation, while maintaining a relatively simple linear form for where we can easily do backpropagation.
, including a neural network, a linear transformation, or some other transformation, while maintaining a relatively simple linear form for where we can easily do backpropagation.
The mapping  tell us about the ‘starting’ importance of different positions, before observing the data . For instance, in [3] they used
tell us about the ‘starting’ importance of different positions, before observing the data . For instance, in [3] they used  the canonical basis vectors. Intuitively, this says that before observing , you assign uniform importance to different locations. Then, the data updates this with . We could also start with something else i.e. exponential decay, a kernel smoother, etc.
the canonical basis vectors. Intuitively, this says that before observing , you assign uniform importance to different locations. Then, the data updates this with . We could also start with something else i.e. exponential decay, a kernel smoother, etc.
Softmax Attention
In practice most papers use some form of softmax attention. It turns out that this framing of maximizing the similarity (inner product) between the attention weights and a summary of the data, while penalizing the attention weights to be more uniform gives us softmax attention
(7) 
Using an Attention Mechanism in a Prediction Model
The real power of an attention model comes from training it end-to-end along with a prediction model. We can learn both the model where we input  and output predictions, and the parameters
and output predictions, and the parameters  jointly. We’re thus learning a summary of the data such that when we use attention weights that are approximately in the direction of this summary to compute a weighted expectation of a data representation, we make good predictions.
jointly. We’re thus learning a summary of the data such that when we use attention weights that are approximately in the direction of this summary to compute a weighted expectation of a data representation, we make good predictions.
[1] Martins, André, et al. “Sparse and Continuous Attention Mechanisms.” Advances in Neural Information Processing Systems 33 (2020).
[2] Blondel, Mathieu, André FT Martins, and Vlad Niculae. “Learning with Fenchel-Young losses.” Journal of Machine Learning Research 21.35 (2020): 1-69.
[3] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).