Popular papers often have code on Github, but the authors are super busy writing new papers, so you may notice that they stop making updates. Eventually certain parts of their code get deprecated and stop working, or bug fixes don’t happen. This is understandable as maintaining a library is a lot of work and the upside in academia is really in writing more papers. However, what do you do then if you find that something breaks/doesn’t run?
One way to handle this is to look at the forks. For example, I recently tried running the code from the latent ODE paper [1] https://github.com/YuliaRubanova/latent_ode. Most of the functions worked pretty well, however, when I tried running the plotting code
python3 run_models.py --niters 500 -n 1000 -s 50 -l 10 --dataset periodic --latent-ode --noise-weight 0.01 --viz
Sampling dataset of 1000 training examples
/home/amoreno32/latent_ode/run_models.py
run_models.py --niters 500 -n 1000 -s 50 -l 10 --dataset periodic --latent-ode --noise-weight 0.01 --viz
Computing loss... 0
Experiment 47844
Epoch 0001 [Test seq (cond on sampled tp)] | Loss 2628.791992 | Likelihood -2637.361328 | KL fp 5.6897 | FP STD 0.7498|
KL coef: 0.0
Train loss (one batch): 2605.57373046875
Train CE loss (one batch): 0.0
Test MSE: 0.5282
Poisson likelihood: 0.0
CE loss: 0.0
plotting....
Traceback (most recent call last):
File "run_models.py", line 326, in <module>
experimentID = experimentID, save=True)
File "/home/amoreno32/latent_ode/lib/plotting.py", line 418, in draw_all_plots_one_dim
plot_vector_field(self.ax_vector_field, model.diffeq_solver.ode_func, model.latent_dim, device)
File "/home/amoreno32/latent_ode/lib/plotting.py", line 108, in plot_vector_field
zs = torch.cat((zs, torch.zeros(K * K, latent_dim-2)), 1)
RuntimeError: Expected object of backend CUDA but got backend CPU for sequence element 1 in sequence argument at position #1 'tensors'
It crashes, saying that it expected a CUDA object but instead got a CPU object. I could investigate why this is an issue and try to fix it from first principles, but sometimes it’s also helpful to see if anyone else has done the fix. Looking at the forks can be helpful. In Github it’s at the upper right of the repo

We see that 49 people have forked the project, and here is a list.
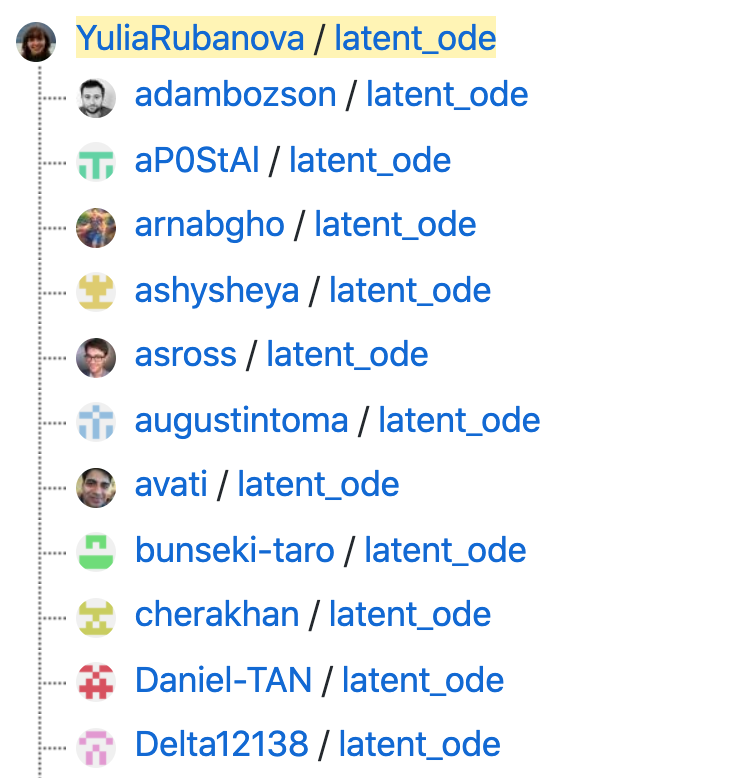
Let’s click on the third one.
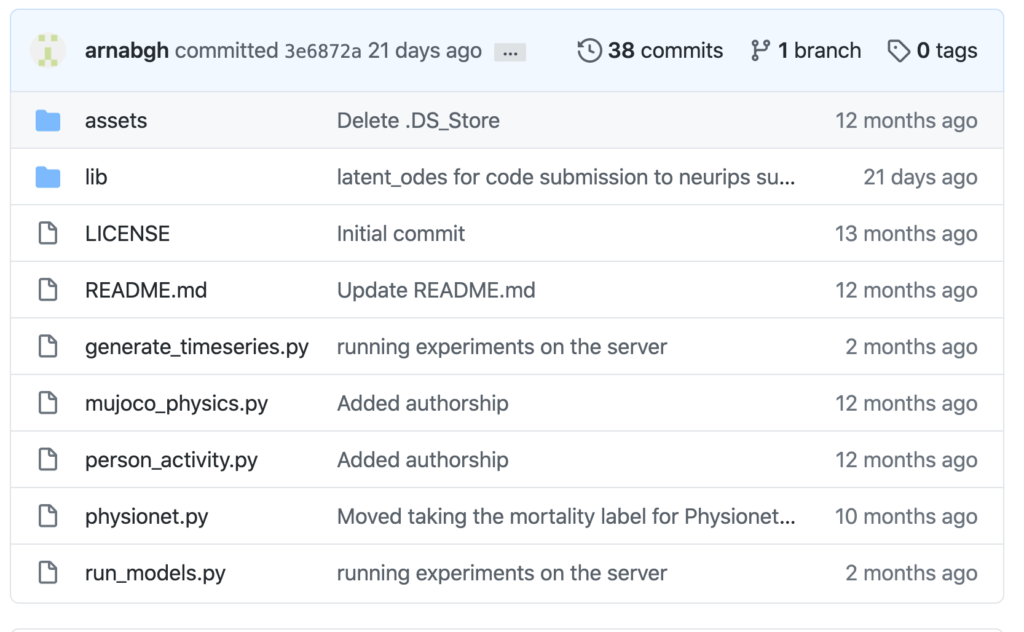
This person has made multiple commits, and has recent edits. Thus, their code is likely to work. By going to the file and line in question that caused the crash, we see that in the original file, we had
zs = torch.cat((zs, torch.zeros(K * K, latent_dim-2)), 1)
while in this person’s repo, they have
zs = torch.cat((zs, torch.zeros(K * K, latent_dim-2).to(device) ), 1)
which moves the relevant tensor from the CPU to the GPU. We can now run the same code:
run_models.py --niters 500 -n 1000 -s 50 -l 10 --dataset periodic --latent-ode --noise-weight 0.01 --viz
Sampling dataset of 1000 training examples
/home/amoreno32/latent_ode/run_models.py
run_models.py --niters 500 -n 1000 -s 50 -l 10 --dataset periodic --latent-ode --noise-weight 0.01 --viz
Computing loss... 0
Experiment 23596
Epoch 0001 [Test seq (cond on sampled tp)] | Loss 2628.791992 | Likelihood -2637.361328 | KL fp 5.6897 | FP STD 0.7498|
KL coef: 0.0
Train loss (one batch): 2605.57373046875
Train CE loss (one batch): 0.0
Test MSE: 0.5282
Poisson likelihood: 0.0
CE loss: 0.0
plotting....
Computing loss... 0
The plotting finishes successfully this time! As a summary, the steps are:
- Look at the forks
- Look at whether this fork has been updated recently
- Check the offending lines and see if they’re different in this fork
Hopefully this helps you out when using code bases on github.
[1] Rubanova, Yulia, Ricky TQ Chen, and David K. Duvenaud. “Latent ordinary differential equations for irregularly-sampled time series.” Advances in Neural Information Processing Systems. 2019.